 Figure One
Figure One
Figure One
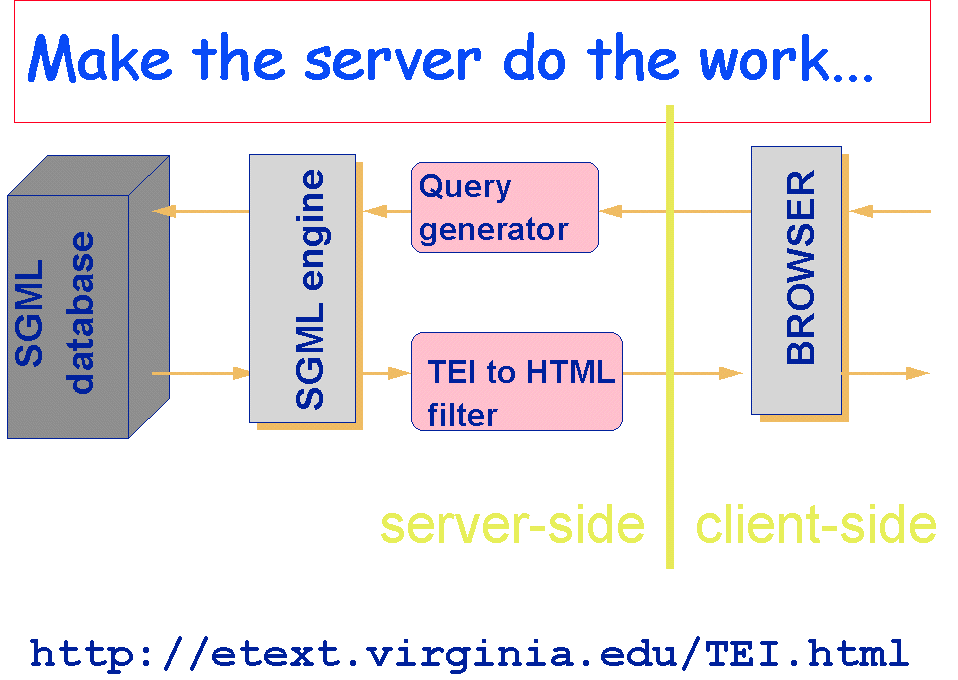
Figure 1 shows the kind of architecture already widely deployed by a significant number of information providers on the web. Information is stored, managed, retrieved and displayed under the control of an SGML aware DBMS of some kind. For the purposes of this argument it makes no difference whether this DBMS in fact handles native SGML or uses some kind of surrogate storage such as a traditional relational database interfaced with a document store. Queries against the database are made via an HTML interface, translated on the fly into SGML queries at the server end; results from the database are dynamically down-translated to HTML for transmission to the client. Several major SGML vendors already market products which perform in this way (examples include EBT's dynaWeb and Open Text's Latitude); moreover the complexity of implementing this solution with existing programming tools via the CGI interface is well within the scope of any competent web programmer.
The strengths of this approach are largely self evident. Any existing investment in a substantial SGML repository is protected, while the benefits of future investment and development in such a system can be passed on in terms of an enhanced service. Serving HTML is essentially no different from choosing any of the other many different publishing media which such central repositories expect to have to support during their lifetime. Service providers enjoy all the advantages of using SGML for resource management as outlined above. The major drawback to this solution lies in its high set-up cost, the need to develop application-specific translators, and the possible need to fine-tune the system for optimal performance, all of which may make it unattractive for small repositories. These costs should however be weighed against the benefits of providing a more responsive and sophisticated enquiry system, able, for example, to deliver just the portion of a large document which is required. Less obviously, it should be noted that the effect of this architecture is to reduce the HTML client to the status of a second class citizen, unable to access directly the full complexity of the document repository.
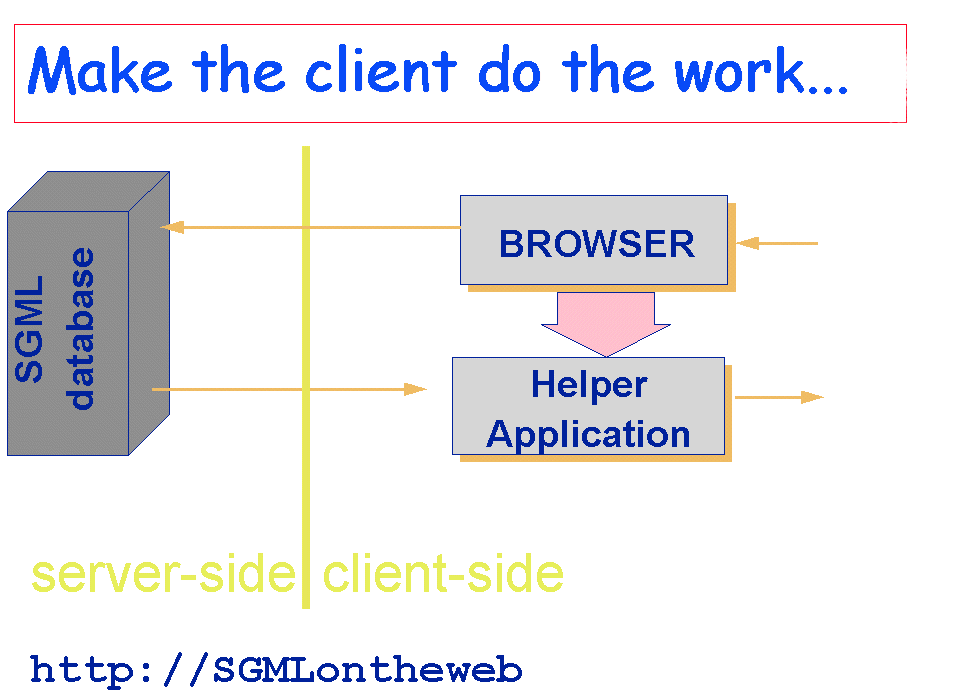 Figure TwoHere the
responsibility for generating SGML-aware enquiries and for handling the
SGML result stream is devolved to the client. In practice, most
currently existing implementations of this strategy focus only on the
second part of the problem. SGML objects are regarded as special kinds
of document, with an appropriate MIME-type which the browser must be
configured to handle appropriately. Any SGML-aware browser or
application could be used to do this, but at present the world's current
favourite appears to be Softquad's Panorama, no doubt largely because a
free version of this browser is available.
Figure TwoHere the
responsibility for generating SGML-aware enquiries and for handling the
SGML result stream is devolved to the client. In practice, most
currently existing implementations of this strategy focus only on the
second part of the problem. SGML objects are regarded as special kinds
of document, with an appropriate MIME-type which the browser must be
configured to handle appropriately. Any SGML-aware browser or
application could be used to do this, but at present the world's current
favourite appears to be Softquad's Panorama, no doubt largely because a
free version of this browser is available.
The success of this strategy depends crucially on the extent to which the helper application is tightly coupled with the user agent which has launched it. If, for example, the SGML document contains links to other documents, it is rather important that the browser can hand these back to the user agent for processing in a seamless and efficient manner. Equally, when the user agent invokes the SGML browser it is rather important that it provide all the environmental resources needed for it to do its job, for example a DTD and a stylesheet, or their equivalents.
SGML-aware JAVA and ActiveX add-ons for existing user agents will no doubt come to market sooner rather than later, with consequent improvements in performance and facilities. (Some have remarked that [quot ]SGML gives JAVA something to do[quot ]). It remains to be seen however how effectively they can address the first half of the problem touched on above: the need to address SGML objects or document fragments of which only the server has knowledge. This is particularly true of metadata, and essential for true distributed document processing.
One does not need to think very long or hard about the functionality needed before it becomes apparent that the combination of user agent plus SGML-aware browser is beginning to look very much like a new form of user agent entirely: a generic SGML client. I will conclude therefore by discussing some aspects of the case for expecting full generic SGML support from web clients.