Electronic Textual Editing: Philosophy Case Study [Claus Huitfeldt, Department of Philosophy, University of Bergen ]
Contents
- Background
- Wittgenstein's Nachlass
- Why a Documentary Edition?
- Contents of the Edition
- Some Key Figures
- Aims of the Edition
- Primary Format
- Consistency of Encoding
- Consistency of Editing and Interpretation
- Basic Requirements
- Formalisation and operationalisation
- Transcription Method
- Representation and Interpretation
- Conclusion
Background
Wittgenstein's Nachlass - The Bergen Electronic Edition: was published at Oxford University Press in 2000. 1 This electronic edition is the first publication of the Austrian philosopher Ludwig Wittgenstein's (1889-1951) complete philosophical Nachlass. It contains more than 20,000 searchable pages of transcription, as well as a complete colour facsimile. The contents and the scale of the edition as well as the editorial methods employed should make it relevant not only to Wittgenstein scholarship, but also to computer-based textual criticism in general.
Wittgenstein himself published only one philosophical book: Tractatus Logico-Philosophicus: . Yet he left behind approximately 20,000 pages of un published manuscripts. Important parts of this Nachlass: have been edited and published posthumously (Wright). Even so, more than two thirds of the Nachlass remained unpublished until the appearance of the electronic edition (Pichler, in Biggs and Pichler).
Some of the previously published editions are selections from several different manuscripts, but their relationships to the manuscripts are not recorded in any detail. The editions are results of different editorial approaches to the manuscripts, some of them containing a lot of editorial intervention, others less. Most of them contain no critical apparatus or other detailed documentation of editorial decisions. Given this background, it is no wonder that for a long time there was a demand for a complete, text-critical edition of the entire Nachlass.
Wittgenstein's Nachlass
Like many other modern manuscripts, Wittgenstein's writings contain deletions, overwritings, interlinear insertions, marginal remarks and annotations, substitutions, counterpositions, shorthand abbreviations, as well as orthographic errors and slips of the pen.
A particular problem is posed by Wittgenstein's habit of combining interlinear insertion, marking, and often also deletion, to form alternative expressions. In some cases he has clearly decided in favour of a specific alternative, in others the decision has been left open. Moreover, Wittgenstein had his own peculiar editorial conventions such as an elaborate system of section marks, cross-outs, cross-references, marginal marks and lines, various distinctive types of underlining, and so on.
Many of these features are results of Wittgenstein's continuous efforts to revise and rearrange his writings. Some of the revisions consisted in copying or dictating parts of the text of one manuscript into another. The Nachlass therefore contains several ‘layers’ or stages of basically similar pieces of text. These inter- and intra-textual relationships are complicated and by no means fully known, but of distinctive interest to scholars studying the development of Wittgenstein's thought.
Why a Documentary Edition?
In consideration both of the nature of the Nachlass: itself, and of its relationship to the existing posthumously published editions, it was by no means obvious what a complete, scholarly edition of the Nachlass ought to look like.
On the one hand, the repetitive nature of the Nachlass seemed to call for a synthetic, text-critical edition of some kind, where different versions of largely identical texts in different manuscripts would be represented in the form of variants on one base text. Yet editorial decisions in general, and the choice of base text in particular, would be interpretationally debatable and problematic in relation to the philosophical audience the edition was supposed to serve.
On the other hand, a documentary edition reproducing the large number of revisions and rewritings page by page, manuscript by manuscript, seemed to lead to a massive, confusing and unnecessary duplication of basically identical material. To some extent this confusion could no doubt be remedied by cross-referencing between the different versions. But such cross-referencing might easily become so extensive that it would just add to the complexity of presentation.
The problems with a documentary edition, however, were considered acceptable if the edition was to be published in electronic form. First, the bulkiness of a documentary edition is easier to deal with in electronic form. Second, an electronic edition is more open-ended and flexible than a book edition.
It was therefore decided to go for an electronic, documentary edition. There was (and still is) no intention to publish this edition in book form. However it may clearly provide the basis for a synthetic edition, should that prove desirable in the future.
Contents of the Edition
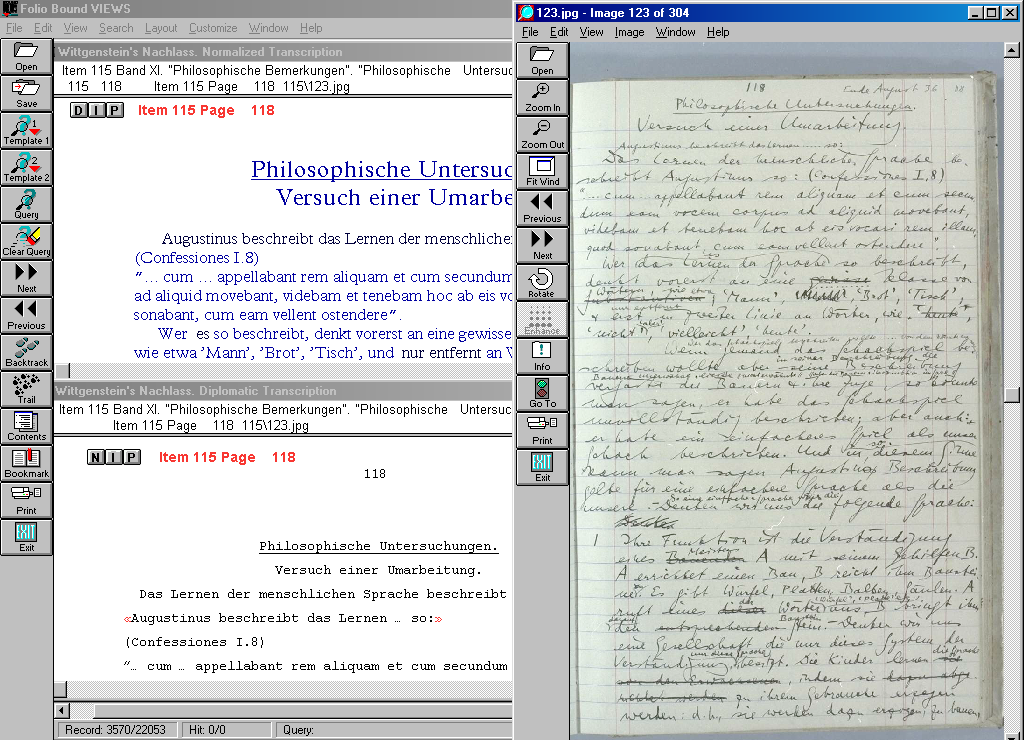
Wittgenstein's Nachlass - The Bergen Electronic Edition : consists of three main components: A facsimile, a diplomatic transcription and a normalised transcription. These three components constitute three interrelated, but independent, ‘views’ to the entire Nachlass.
The facsimile simply consists of digital, high-quality colour images of each and every page of the Nachlass.
The diplomatic and normalised transcriptions are differentiated, not so much in terms of how much detail they convey, but rather in virtue of their textual perspectives.
The diplomatic version records faithfully not only every letter and word, but also details relating to the original appearance of the text. One might say it acknowledges that our understanding of the text derives in no small part from the visual appearance of material on the page. It reproduces features such as deleted words and letters, shorthand abbreviations, orthographic inconsistencies, rejected formulations, authorial instructions for the re-ordering of material, marginal comments, etc. It has been assumed that one of the principal uses of the diplomatic text will be as an aid to reading the facsimile.
The normalised version, on the other hand, presents the text in its thematic and semantic aspect. Orthography is corrected to a standard form, slips of the pen and deleted materials are suppressed, shorthand abbreviations are extended, and unequivocal instructions for the reordering of material are carried out. Variants have been merged to alternative readings, only one of which is always visible on screen, while the others may be displayed upon request. The result is a version which is easy to read and suitable for searching for words and phrases.
Some Key Figures
As already mentioned, the edition covers 20,000 pages, which are all presented in the three alternative formats just discussed. The 20,000 pages comprise altogether 3 mill words, and in order to interlink the three versions approximately 200 000 links have been created. In addition, there are a few thousand links representing Wittgenstein's own cross-references. The source transcriptions from which the edition has been derived (see below) contain approximately 2 million coded elements (not including entity references, or codes for special characters).
Even though partly based on work done prior to this project (Huitfeldt and Rossvær), it took almost ten years to complete. The Wittgenstein Archives at the University of Bergen spent altogether 40 man-years (including, in addition to text transcription and editing, also management, administration, systems development and maintenance and all other tasks related to the project.) This should give an average throughput of two pages per person per day, which must be considered high compared to most other editorial projects.
Aims of the Edition
In the preparation of this edition, basic requirements guiding the work of the Wittgenstein Archives were the following: Transcriptions should provide a fully sufficient basis for the production of both (1) diplomatic and (2) normalised versions of each and every manuscript. Transcriptions should also be suited for (3) searches for words, strings and content elements, and cross-referencing. In addition, transcriptions should include information facilitating (4) grammatical analysis, and segmentation according to alternative criteria.
It was considered of utmost importance that the edition should document manuscript details according to the highest possible standards of text-critical accuracy, that it should apply a uniform and consistent set of editorial principles throughout the entire Nachlass: , and that it should document the exact Nachlass sources for each and every piece of text.
Ideally, transcriptions should not only (though most importantly) be accurate and interpretationally sound, consistent and systematic, but also falsifiable. In other words, transcription should be guided by explicit rules such that anyone who endeavoured to repeat transcription according to these rules would, as far as possible, end up with identical results.
Primary Format
These requirements often implied conflicting demands. In particular, implications of the requirement for a diplomatic version easily conflicted with the other requirements. Yet for a number of reasons, most notably the concern for secure and reliable data maintenance, it was decided that for any given manuscript we wanted one and only one source transcription to serve all our purposes.
Out of concern for the longevity of the work it was also considered imperative that the format of the source transcriptions should as far as possible be hardware- and software-independent. It was decided to use a declarative text encoding system, i.e. to mark textual features explicitly according to a formal syntax which would enable us to produce secondary versions which satisfied the demands set forth above by means of off-the-shelf or specially designed software.
At the time when the Wittgenstein Archives was established, Standard Generalized Markup Language (SGML) was the only serious international standard to be considered (SGML). However, it was decided not to use SGML for this project. Instead, a special code syntax was developed for the Wittgenstein Archives, and software which allowed for flexible conversion to other formats was developed. This system was called Multi-Element Code System (MECS) (Huitfeldt, Multi-Element).
One of the reasons for not choosing SGML was that SGML had problems representing overlapping and other complex textual features. Another reason was that little relevant software for SGML existed, and there was little experience available from applying SGML in scholarly editorial work (The Text Encoding Initiative's Guidelines did not yet exist at the time.) Therefore, MECS was designed to overcome some of the problems with SGML and to provide software support for text-critical purposes beyond that provided by SGML at the time. In all other respects, MECS was kept as close to SGML as possible.
However, neither the reasons for the decision not to use SGML and to develop a special code system for the Wittgenstein Archives, nor the differences between SGML and MECS, are of any concern for the purposes of this discussion (but see Sperberg-McQueen and Huitfeldt, “Concurrent.” and “GODDAG.” ). Instead, I will focus on examples taken from the SGML-based encoding scheme developed by the Text Encoding Initiative, since this is more widely known then the MECS-based encoding scheme used at the Wittgenstein Archives.
Consistency of Encoding
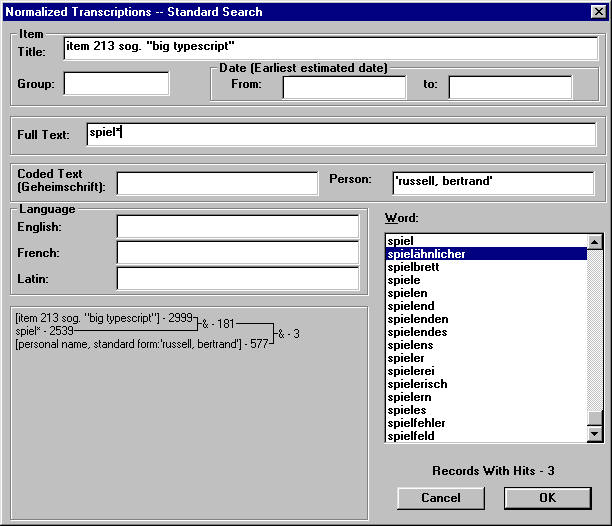
The TEI Guidelines provides various alternative mechanisms for the encoding of many (or even most) textual phenomena. This is one of the strengths of the Guidelines, and one of the reasons why the TEI Guidelines are found applicable to a large number of widely different projects involved in text encoding. At the same time, this openness and flexibility poses a danger of inconsistency.
For example, abbreviations may be encoded in basically two different ways according to the TEI Guidelines. Take the German abbreviation 'dh', which normally stands for 'das heißt' ("id est", "that is"). 'dh' may be encoded either as follows:
(1) <abbr expan='das heißt'>dh</abbr>
or as follows:
(2) <expan abbr='dh'>das heißt</expan>
A stylesheet specifying that the content of an abbr element should be replaced by its expan attribute value, while an <expan> element's content should be printed as is, would display both (1) and (2) as 'das heißt'. Correspondingly, a stylesheet specifying that the content of an <abbr> element should be printed as is, while the content of an <expan> element should be replaced by its abbr attribute value, would display both (1) and (2) as 'dh'. Any other combination of specifications would treat the two alternative representations of the same abbreviation differently.
There may indeed be a case for treating different instances of the same abbreviation differently (depending, for example, on context), but if the choice of representational form is left completely undecided by rules governing transcription and editing, the path to inconsistency is wide open. On the other hand, there may be a case for treating different abbreviations differently, independently of context.
For example, the German abbreviation 'dh' is a commonplace and may be regarded as a standard abbreviation, whereas the abbreviation 'Psych', as found in certain places in Wittgenstein's Nachlass, is by no means a standard abbreviation. It may be an abbreviation for 'Psychologie', 'Psychologisch' or 'Psychisch' ('psychology', 'psychological', or 'psychic', respectively), depending on context and interpretation. (German capitalisation rules is a further complication not taken into consideration here.)
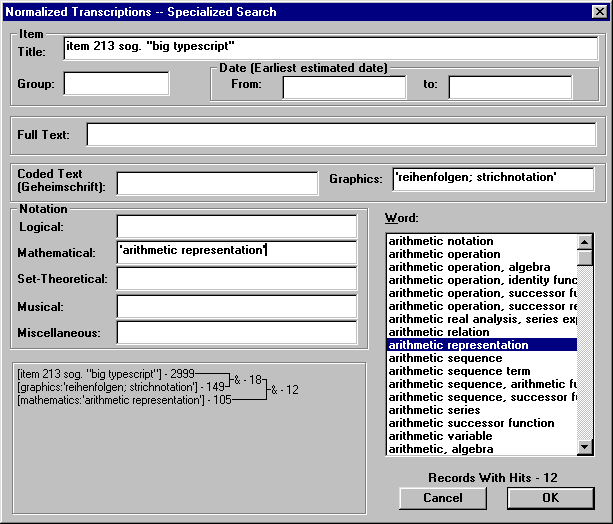
In SGML element content can be marked up, but attribute values cannot. In other words, if a distinction is made between standard and non-standard abbreviations, and there is a need to mark up both, neither of them should be represented as attribute values.
One of the great advantages of text encoding systems like SGML is that they allow for automatic validation of document structure. What is checked, however, is the structure of the encoding, not the contents of text elements or attribute values of type text. In some cases there is a need to check the contents of standard and non-standard abbreviations separately. (For example, it may be desirable to check both against a list of standard abbreviations.) In such cases, both should be represented as element content, though of different element types.
The Wittgenstein Archives decided to make a distinction between standard and non-standard abbreviations, and to represent both as element content. (Had we used the TEI Guidelines, we might have used the abbr element for the former and the expan element for the latter.) The point of this discussion is not, however, to advocate the particular approach taken by the Wittgenstein Archives. The point is to illustrate that for virtually every textual phenomenon to be encoded, each project needs to reflect on issues like these in order to ensure the desired level of consistency.
Consistency of Editing and Interpretation

In order to comply with the Wittgenstein Archives' requirements for the diplomatic version, one has to account for the facts that "weiße" is inserted above the line, that "Schloß" is overstriked, and that "große" has been misspelt "grosse".
- das große weiße Haus
- das große weiße Schloß
- das große Schloß
- das weiße Haus
- das große Haus
- das weiße Schloß
In text-critical work, one will invariably rely on transcribers and editors to make their choice of possible readings using their best judgement based on thorough knowledge of the author, the history of the text, its historical and cultural context and other interpretationally relevant factors. Quite often, however, such considerations do not decide matters of details like these with any degree of certainty. In such situations, leaving the choice of readings entirely to the individual transcriber without further guidance is almost certain to lead to inconsistency.
According to the editorial principles employed at the Wittgenstein Archives, the example above has exactly two readings: (a) and (b) — these and no others, neither more nor less (unless interpretational considerations decide otherwise). We will not go into the details of the principles leading to this decision here. Which principles to employ in the choice of readings may always be discussed, and will vary from project to project. In the interest of consistency however, it is usually important to ensure that such situations are always treated the same way within the same project.
Basic Requirements
One might say that the aim of a diplomatic representation is to get every letter of the original right, whereas the aim of a normalised representation is to get every word and every reading right. So what we need in order to ensure consistency and reliability of transcription is criteria of what is to count as correct, as well as procedures which may help transcribers come up with the right solution in each particular case.
The following is a brief description of the criteria and procedures developed and employed at the Wittgenstein Archives. As mentioned, the Wittgenstein Archives did not use the TEI Guidelines, or indeed even SGML. However, the criteria and procedures discussed are entirely independent of such technicalities, and could equally well be adopted by e.g. TEI-based projects.
Let us start with the criteria for ensuring that a transcription is suited for diplomatic reproduction of the original text: It is not obvious what this means. According to some conventions a diplomatic reproduction retains an almost exact positioning of every text element in two-dimensional page space, faithfully reproduces differences between allographs of the same graphemes, and represents visual markings like strikeouts, underlinings etc. as close to the original in their visual appearance as possible.
The Wittgenstein Archives decided for a less strict definition: The diplomatic reproduction should reproduce the original grapheme by grapheme, contain indication of indentation and relative spatial positioning of text elements on the page, and include information about deletion and interlinear insertion and a number of different kinds of underlining. It was not considered necessary, however, to indicate every line break or allograph variation.
Consequently, the markup system contained markers for phenomena of the kinds mentioned, and the procedure followed by transcribers was simply to mark up every such phenomenon with the required element. By means of a style sheet the marked up features were reproduced according to certain conventions, and the correctness of transcriptions was checked by visually comparing the output with the original text.
The criteria for ensuring that a transcription is suited for normalised reproduction were less easy to formulate, and were dealt with by means of a much more elaborate and formal approach, to be described in the next two sections.
Formalisation and operationalisation
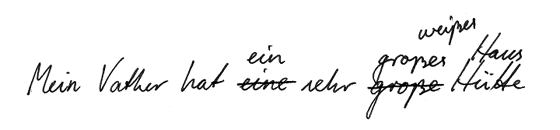
Again, an obvious requirement for a normalised reproduction is that orthographic errors are corrected. In this example one will have to mark up the misspelling 'Vather' so that it can be rendered correctly as 'Vater' in the normalised version. Admittedly, orthographic rules are not always clear, and texts are frequently written according to idiosyncratic or inconsistent orthographies. Further complication are that orthography variation is quite often a literary means of expression, and that orthography may in itself be an object of study. In electronic texts spelling affects not only readability, but also retrieveability. Therefore, standardisation is much more important in electronic than in traditional editions. While there may be a need to retain the original orthography, as in diplomatic transcription, there is also a need to standardise orthography to some set of uniform spelling rules.
- Mein Vater hat eine sehr große Hütte
- Mein Vater hat ein sehr großes Haus
- Mein Vater hat ein sehr großes weißes Haus
- Mein Vater hat eine sehr große weiße Hütte
As with the previous example, some kind of guidance is needed as to whether all or only some of these are to count as possible readings. However, not every possible combination of substituenda makes sense. For example, even though 'Hütte' has not been deleted, ‘Mein Vater hat ein sehr großes Hütte ’ is ungrammatical and not a possible reading. By mechanically selecting one out of every pair of substituenda, one can create a large number of obviously invalid readings. One needs to mark the text up in a way which does not include these.
We started out by making one basic decision: If among two transcriptions interpretational considerations do not decide clearly in favour of the one rather than the other, we would decide in favour of the one which came closest to an ideal of what we called a well-formed text, which we defined as follows:
A well-formed text is a unilinear sequence of orthographically acceptable and grammatically well-formed sentences which together form a coherent text unit.
Our next step was to define what we called an alpha-text:
An alpha-text is as a set of strings derived from a transcription according to a language-specific procedure.
There was one such procedure for each language present in the transcription. The procedures consisted in assigning functions such as inclusion, exclusion and case change to every element type.
Our final step was to define what we called beta-texts. We observed that whereas a well-formed text was defined as a unilinear sequence of sentences, a manuscript with alternative readings was multi-linear rather then unilinear. We defined a transcription's beta-texts (roughly) as follows:
The beta-texts of a transcription is a set of texts derived by excluding, for every substitution, all except one reading, and repeating the process until all possible combinations of readings of the entire text has been exhausted.
- T1
- Every alphatext derived from the transcription should be a list of orthographically acceptable graphwords in the language of that alphatext.
- T2
- Every betatext derivable from the transcription should be a well-formed text.
To avoid a possible misunderstanding: The set of betatexts derivable from one and the same transcription do not necessarily represent different interpretations of the manuscript in question. If the transcription derives more than one betatext, then that may just as well be regarded as a characteristic of the interpretation in question.
Transcription Method
- RULE A:
- Manuscripts should be transcribed page by page from the front towards the back page, each page vertically line by line from top to bottom, each line horizontally letter by letter from left to right.
The rule may seem too trivial to be of any interest whatsoever. It simply describes one of the most elementary features of the Western writing system. However, with manuscripts like ours, and if taken literally, this rule is almost guaranteed to produce transcriptions which are neither interpretationally acceptable nor well-formed.
- D1.
- It is not possible to satisfy requirements T1 and T2 unless one deviates from Rule A, and no interpretational considerations directly contradict the deviation in question.
- D2.
- Although a transcription according to Rule A satisfies requirements T1 and T2, there is positive evidence in the manuscript in favour of a deviation from Rule A, and the deviation in question does not lead to violation of T1 or T2.
- D3
- . There is positive evidence for more than one reading of a specific word, one or more of these readings will not be included in the alphatext unless one deviates from Rule A, and the deviation in question does not lead to violation of T1 or T2.
Finally, we decided which kinds of deviations or modifications were allowed, and listed them in order of preference as follows:
- Rearrangement
- Simple substitution
- Reiterative substitution
- Extension
- Exclusion
Each of these deviations were in turn defined in terms of specific markup procedures. For example, 'exclusion' did not consist in leaving text out, but in marking it up with an element classified as a "beta-exclusion" or an "alpha-exclusion" code. We shall not go into further detail about these operations here. What is important to note, however, is that the deviations were given an order of priority. This meant that a lower level deviation could only be applied if no combination of higher-level deviations would suffice to satisfy T1 and T2. For example, simple substitution should only be used if rearrangement was not enough; reiterative substitution only if neither rearrangement, nor simple substitution, nor any combination of rearrangement and simple substitution would suffice; and so on.
A transcription of the example from the previous section according to transcription rules defined by our project generates the following alphatext:
mein Vater hat eine ein sehr große großes weißes Hütte Haus
and the following beta-texts:
Mein Vater hat eine sehr große Hütte
Mein Vater hat ein sehr großes weißes Haus
The alphatext satisfies T1, and the betatexts satisfy T2. It is worth noting, however, that while the procedure does produce the readings a) and c), it does not produce b) or d), which also satisfy T2.
Representation and Interpretation
One intriguing aspect of editing philosophical texts is that the editorial work itself exemplifies a number of classical philosophical problems, such as the relationships between representation and interpretation, the subjective and the objective.
Traditionally, it has been assumed that the responsibility of an editor is to provide an objectively correct representation of a text, and that as far as possible editors should avoid interpretation. The edited text is supposed to provide the basis for interpretation of the work in question. Therefore, the edition itself should be as free from interpretation as possible.
As can be gathered from the frequent references to "interpretational considerations" in the discussion above, the work of the Wittgenstein Archives was not based on such a view of interpretation. Even so, the very idea of a diplomatic transcription seems to presuppose the possibility of an objectively true and accurate representation of the original text. In particular, the whole motivation for some of the text encoding practices employed by the project was to ensure the accuracy of the diplomatic representation.
The TEI Guidelines, however, "define[s] markup ... as any means of making explicit an interpretation of a text"(TEI P3, 13). Interpretation, in turn, is described as "information which is felt to be non-obvious, contentious, or subject to disagreement"(TEI P3, 113).
- A text is a representation of another text if the first has the same linguistic content, i.e. the same wording, as the other.
- A text is an interpretation of another text if the first is not a representation of the other, but expresses, explains or discusses the meaning of the other text in other words.
On this background, I propose two steps to get us out of our problem. As a first step, let us imagine representation and interpretation as areas located towards opposite ends of a two-dimensional continuum. Then our task is to find somewhere along this continuum suitably clear demarcation lines, which allow us to decide, in particular cases and classes of cases, what is interpretation and what is representation.
By stating that something is a representation we are not excluding the possibility that it may, given some other demarcation line, legitimately be regarded as interpretive. Nor are we denying that representations and interpretations are, in some perspective, of the same kind. And we are not claiming that there are no difficult borderline cases. But we will clearly come to doubt the usefulness of a demarcation line placed at one extreme of the continuum.
At this point, we can observe that what was called representation above may be said to consist in the identification of the meaning of a text (reading, listening, deciphering). Methods for establishing such representations differ from mechanical methods of representation (such as bit maps, OCR etc.) in that they involve human symbol recognition and understanding, and are therefore sometimes felt to be less objective and reliable. This is probably why such activities are sometimes called interpretive. In accordance with the proposed view, however, we may safely position our demarcation line so that we regard them as matters of representation.
The second step on the way out of our difficulty is this: We should construe it not as a problem about the nature of text encoding, but as a question about the potential capacities of text encoding to create certain kinds of texts, namely representations and interpretations. This move is motivated by the common-sense view I formulated above, according to which representation and interpretation are names for relations, and derivatively, therefore, for certain texts which represent and interpret other texts.
By extending each of these dyadic relationships to a triadic one, between a pair of texts and an audience, we are able to take into account that what the demarcation line between representation and interpretation changes from case to case. This move also reflects the fact that texts are not representations or interpretations of each other in abstraction from their actual uses, but only in relation to certain audiences of human beings, i.e. social, historical and cultural beings. Thus, we may conclude that there is such a thing as objectivity of interpretation: The vast majority of decisions we make in this realm are simply decisions on which all (or most) competent readers agree, or seem likely to agree.
Conclusion
The method described here might easily be criticised for creating an illusion that traditional text-critical scholarship, based on philological knowledge and careful interpretation, can be replaced by mechanical procedures and an artificial definition of the one and only "correct" transcription.
However, the requirements T1 and T2 are not intended to serve as criteria for identifying a correct interpretation of a manuscript. What they do, is to direct our choice among possible interpretations in favour of some (not one) rather than others.
And as is often the case, the method as such does not in principle depend on the use of markup systems, or even on computers. But it is only by marking up texts and using computer tools that the method can be implemented in practice.